

調査班 Rust調査レポート
いやー。今回も箱庭さんに騙されてやってしまいました。
ものっすごっくディーープなRustの海の中に潜ってきました。
私達、調査班はホントはPacketが専門なのですが、またもやこんなカードが机の上に・・・。

はい。パケットのカプセル化は知ってますが・・・。
Arcとは?
そもそも、話の発端は、イーサーネットケーブルを定義しているこの構造体で指定されているstateの型のようです。
#[derive(Clone)]
pub struct EthernetCable {
state : Arc<Mutex<EthernetCableState>>,
}
まさしく箱庭さんが書いていたこの絵のように、カプセル化っぽい。
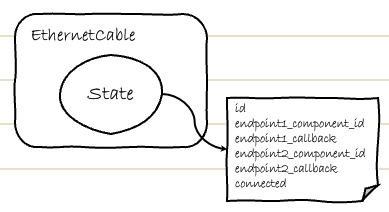
Arc<Mutex<EthernetCableState>>
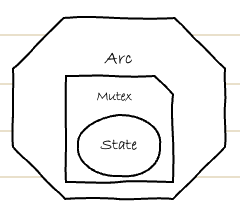
という型が指定されているところを見ると、ArcとMutexで2重に囲われている2重カプセル化?
この絵を見るとその線はあってそうですね。
まずRustの所有権について
Rustでは、通常、データは1つのオーナー(持ち主)しか持てないというルールが決められています。
例えば、ある関数で作ったデータは、その関数の中でしか使えないというルールがあります。 これは、メモリ安全性を保証するためのRustの独特の仕組みです。
fn hello_message(){
let a = "World!";
println!("Hello, {}",a);
}
この変数aは、aを作った関数hello_message()のもの(所有)であり、この関数が終わったら、メモリ上から消えるというルールです。
学生時代に例えると、1冊の英語の教科書は、その人のもの。 という感じです。自分の名前を書いてこの教科書は自分のもの。と所有権を明示していましたね。
Arc
そして、今回登場したArcですが、調べてみたところ、
Arc(Atomic Reference Counting)は、複数の所有者で同じデータを共有できるスマートポインタという仕組みでした。
いきなりこんな1行では難しいですね。分解していきましょう。
「スマートポインター?」
Rustのスマートポインターは、通常のポインターに追加の機能を持たせた構造体であり、
メモリやリソースの管理を簡潔かつ安全にするためのものです。
普通のポインターは、データへの参照(アドレス)を格納していますが、スマートポインターはアドレスだけでなく、所有権のルールや自動的なクリーンアップ機能を提供します。下記の3つの特徴があります。
- メモリ管理を自動化する Rustは所有権ルールを使用してデータ(=メモリ)を管理しますが、スマートポインターを使うことで、複雑なメモリ管理を簡単に処理できます。
- ライフサイクルの安全性を保証 ユーザがデータのライフサイクルを意識しなくても、Rustのスマートポインタは安全なリソースの管理を保証します。
通常ポインター
int* ptr = new int(10); // メモリを手動で確保
free ptr; // メモリを手動で解放
スマートポインター
let smart_ptr = Box::new(10);
// Boxは、Rustでヒープ領域にメモリを確保するスマートポインターの1つ。
// 所有権を持つ関数が終了したら、自動的にメモリも解放される
- 追加機能の提供 データの共有、参照カウント、可変性の制御、データ同期など、基本ポインタにはない便利な機能を提供します。
「複数の所有者?」
「1つのデータに1つの所有者しかないんじゃないの?」って聞こえてきそうですが、同じデータを共有したい時があります。 例えば、教科書を忘れてしまった時、どうしていましたか? 隣の人と机をくっつけて見せてもらったりしませんでしたか?
どうしてもそのシステムの中の1つのデータをいくつかのところで共有したい時が出てきます。
そういう時のために、Arcというスマートポインターの仕組みが作られました。
ただし、そういう特別な用途の場合は、明示的に例えばArcという仕組みを使おうね。と決まっています。
Arcとは
Arc=Atomic Reference Countingは、Reference Counting=参照カウントという仕組みで、
現在このデータを参照している所有者の数を持っています。
誰かが参照している限りはメモリ上で生き続けます。このカウントが0になったら、自動で消える仕組みです。
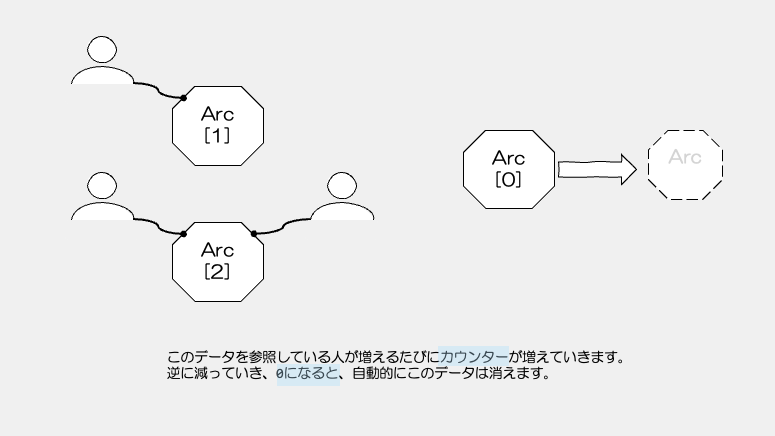
これは、スマートポインターの特徴として最後に挙げた、「追加機能」の部分でこれが可能になっています。(データの共有、参照カウント)
【Atomic Reference CountingのAtomicって?】
Atomicというのは「不可分の」「分割できない」という意味を持つ言葉です。
コンピュータサイエンスの世界では、「原子性」と呼ばれ、操作が途中で中断されたり、他の操作によって影響を受けたりしないことを意味します。
もう分割できない最小単位の処理ということになります。
コンピュータの世界で、その最小単位とは、以下の条件を満たす操作のことを指します。
・不可分性
操作が途中で中断されることはなく、完全に成功するか、完全に失敗するかのどちらか。
・競合の回避
他のスレッドから干渉されず、完全な一貫性が保証される。
Arcは参照カウントを内部でAtomicに操作できるように管理しています。
Atomicに操作(atomic operation)できるとは、「途中で中断されない、分割できない操作」のことを言います。
コンピュータのプログラムにおいて、Atomic操作は、複数のスレッドやプロセスが同時に実行している環境でも、競合や整合性の問題を避けるために使われます。
Atomic操作は、一度実行されると完全に実行されるか、まったく実行されないかのどちらかであり、途中で状態が不安定にならないことが保証されます。
「Atomic操作の特徴」
・途中で中断されない
Atomic操作は、途中で他のスレッドやプロセスに割り込まれることなく、完全に終了します。
これにより、状態の一貫性が保たれます。
・分割できない
Atomic操作は一度始めると、その処理全体が一つの単位で行われ、他の操作に分割されません。
これにより、他のスレッドがその操作の途中結果を読み取ったり、干渉することがありません。
Arcの参照カウントをアップする時に、他の所有者からのカウントアップが重なったりしないよう、
最小単位であるAtomicを使っているということになります。
実際に、Arcの構造体の中で、カウンターは、AtomicUsizeという型で管理されています。
Arc=Atomic Reference Counting
ここまで順番に分解してきたことを、つなぎ合わせてみましょう。
Atomicな操作で、所有者同士の競合が起きないように参照カウンターを管理操作して、
複数の所有者でこの中のポインターが指すアドレスにあるデータを管理する仕組み。
と、どうですか?ここまで読み進めるとこの言葉の意味が分かるようになったのではないでしょうか?
今回、EthernetCableStateをArcにした理由は?
今回箱庭さんが、EthernetCableStateをArcで囲った理由を考えてみました。
・Javascript側とWASM側で複数のスレッドで動く可能性があるから。
・シミュレーターでは各ネットワークコンポーネントが非同期に動く=WebWorkerなどで別スレッドで動く
・複数のスレッド、ネットワークコンポーネントから参照されてもID=1のケーブルは「1つ」でないと電気信号のやり取りができなくなるから。
こういうことなのではないかと推察できます。
「複数の所有者がいるの?」
「はい!います。」
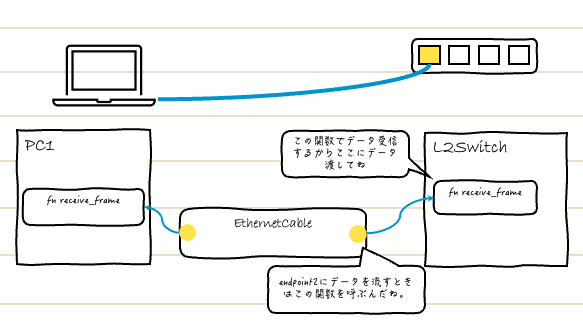
この絵を見てください。
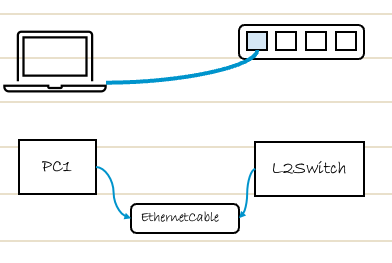
1つのケーブルが、PCと、L2 Switchの2つに繋がっていますね。
そもそもケーブルの働きって、2つのものを繋げてその間に電気信号を流すことですから、このように、最低でも2人の所有者がいるわけです。
PCとL2 Switchは現実の世界でも同期して動いてはいないですよね?
PCはPC、L2 SwitchはL2 Switchでそれぞれ別々に動いています。
このような状態のことを別スレッドといいます。
それぞれがスレッドとして同じ世界=同じプログラムの中で動くことができる仕組みです。
PCはPCで時間軸を持ち自分のタイミングで動いています。
L2 SwitchもL2 Switchで自分のタイミングで動いています。ね。
同期をとってPCがこうしてらからL2 Switchが次こう動くというわけではなく。
それぞれの時間軸で自分のはたらきをすること。それがスレッドという概念です。
シミュレーターの中では、現実世界と同じく、同じプログラムの中で、PCスレッドとL2 Switchスレッドが、それぞれの時間軸で非同期に動きます。
もちろんイーサーネットケーブルも独自の時間軸で電気信号を自分の帯域スピードで送受信します。
(今回の抽象化では、電気信号を流すことが主な働きとしてクローズアップされましたが、種類によって帯域や、スピードなど他にも色々なことがイーサーネットケーブルの特徴としてあります。)
しかしこの2つを繋げている、イーサーネットケーブルは1つしかありません。いえ1つでないと困るのです。
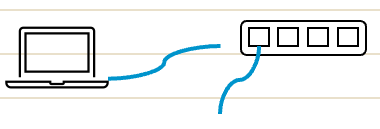
この絵のように、それぞれが独自のケーブルを持っても、通信できませんよね。
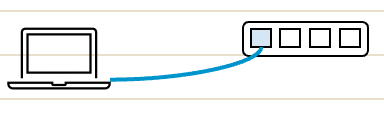
ですので、今回、箱庭さんが、EthernetCableStateをArcにしたのは、そういう理由からだと思うのです。1つにして、それぞれの所有者からのリクエストに応え、安全に電気信号を送受信するためなのです。
Mutexとは?
さて、次にMutexとは?
Arcではできないこと
Arcだけでは、複数の所有者からの参照はうまく管理できるのですが、複数の所有者からの更新は管理できません。
そこで、登場するのが、Mutexという仕組みです。
Mutexの基本的な概念は、「相互排他」(Mutual Exclusion)から来ているそうです。 これは、複数のスレッドが同時に同じデータにアクセスすることを防ぐ仕組みです。
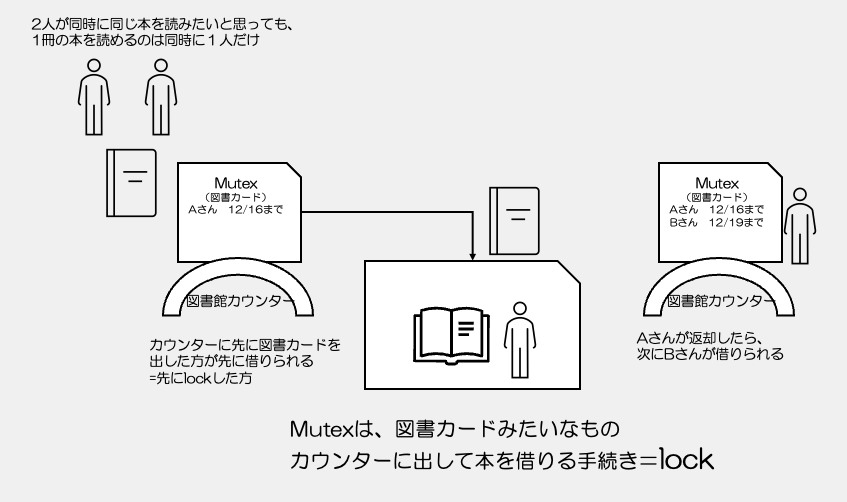
例えば、図書館の本を想像してみてください。
ある本を2人の人が借りたいと思っても1冊しかないとすると、
その1冊の本を借りれるのは、1人だけですね。
図書館のカウンターで図書カードに書いてもらって、手続きをして、借ります。
そして読み終わったら、返す。
そうしたら、次の人が借りることができるようになる。
という、この流れを作り出すのがMutexです。
Mutexの重要なポイント
・安全な共用
複数のスレッドが同時に同じデータを変更することを防ぎます。
.lock()メソッドを呼び出すと、他のスレッドはそのデータにアクセスできなくなります。
・RAII(Resource Acquisition Is Initialization)
ロックは自動的に解放されます。
スコープを抜けると、自動的にロックが解除されます。
・注意が必要なデッドロック
1つのシステムの中で複数のMutexを使う際は注意が必要です。
不適切な順序でロックを取得すると、デッドロックが発生する可能性があります。
といったことがMutexを使う上でのポイントになります。
Arc+Mutex
さて、ここで本筋に戻りましょう。
Arc<Mutex<EthernetCableState>>
という風に定義することで、
複数のスレッドがArcで所有権を共有し、同じイーサーネットケーブルのオブジェクトを共有することができるようになります。
そして、それぞれが非同期で動く環境では、それぞれが、それぞれのタイミングで、更新処理しようとするとおかしくなってしまうので、Mutexでガードして、安全に共有されているオブジェクトを利用することができるようになります。
今までの構造体は、PacketやAddressといったデータを表現する構造体で、型を定義している感じでしたが、これから作るネットワークコンポーネントではそれぞれの「はたらき」もあり、通信するために接続されたそれぞれの機器が、その「はたらき」を処理していきますので、箱庭さんは今回こういう感じの構造体にしていったということでしょう。
安全に共有されているオブジェクトを利用すると言うと、Mutex単独だけでもいけるんじゃないか?と思いませんか?
私もその疑問が出てきて調べたところ、Mutex単独では、複数のスレッド間でのデータ共有はできず、所有権を持つスレッド内でしか使用できないため、他のスレッドに安全に渡す方法がないということでした。
スレッド間で所有権を渡せるには渡せるのですが、共有データのライフタイムを正しく管理する必要があります。これを手動で行うのは非常に困難そうでした。
データの共有(=Arc)と、データの共用(=Mutex)というセットで使うようにしましょう。
ArcとMutexで囲んだ場合のメモリ構造について簡単な図で確認しましょう。
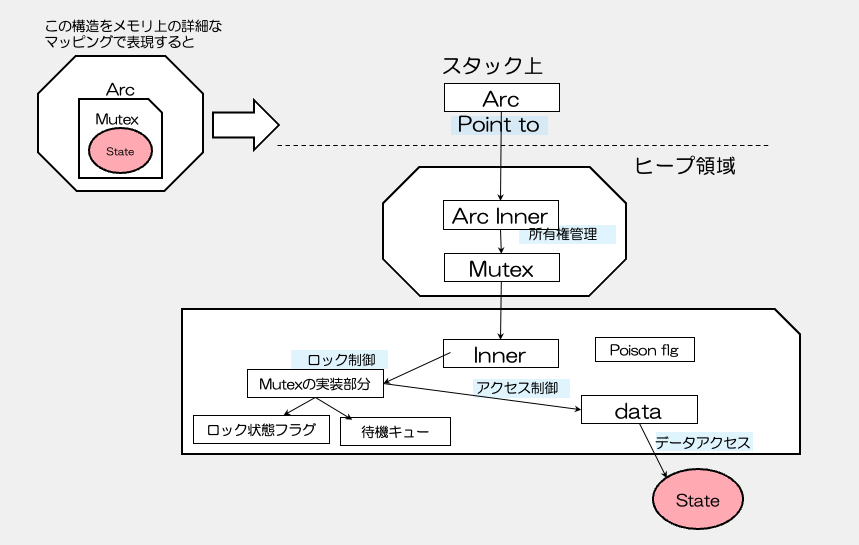
このような構造になっています。スタックと呼ばれる小さな領域にArcは置かれています。
高速にアクセスできる場所です。
そして、ヒープ領域という膨大なメモリ領域の中の1つに、ArcInnerというArcの中身がおいてあります。
スタック上のArcはこのArcInnerのアドレスを指しています。このArcInnerが所有権を管理して
参照カウンターを持っています。
さらに、この中にMutexへのポインターがあり、Innerと呼ばれるMutexの実態のアドレスを指しています。
そして、その中から、ロック制御を行うMutexの実装部分があり、そこでロック制御をしています。
その中から、Data部分へのアクセス制御をしています。
このあたりが図書館の受付カウンターみたいなものですね。
そして、dataが実際のデータ領域へのポインターになっておりデータを取り出せます。
Arc<Mutex<EthernetCableState>
のメモリ構造は、こういう構造です。
Rustの他のスマートポインターと呼ばれるものも大体同じような構造でした。
さて、ちょっと気になるようなワードが、Mutexの中にありますね。見ていきましょう。
「poison flg」というのは、複数のスレッドの中で、ある1つのスレッドがパニックすると、そのスレッド内の操作が途中で中断されます。中断したスレッドがMutexを保持していた場合、そのロックが解除されますが、共有データ(ここでいうState)が不整合な状態にある可能性があります。
そのまま、他のスレッドがこの不整合なデータにアクセスすると危険ですので、Mutex内部のPoison Flagが設定されます。
この状態のMutexを「毒されている (Poisoned)」と呼びます。
他のスレッドがロックを取得しようとすると、MutexはErrを返し、ポイズン状態を通知します。
この仕組みにより、不整合なデータへのアクセスを防ぐことができるようになっているのです。
図書館で借りた本を読んでいて、ラストシーンの部分のページが抜け落ちていたら、ガッカリしてしまいますよね。そんな悲しいことにならないように優秀な司書さんが事前にこの本は借りられません。って言ってくれてるようなものですね。
PhysicalLayerCallback
さて他にも、みたことがないような型がありますね。
pub endpoint1_callback : Option<PhysicalLayerCallback>,
pub endpoint2_callback : Option<PhysicalLayerCallback>,
このフィールドは、
・イーサーネットケーブルの端の1つに繋がったコンポーネントが、
・データを受信するときはここで受信するからここにデータを送ってね。という関数を、
・イーサーネットケーブル側で覚えておくためのフィールドになります。
イーサーネットケーブルの両端を表すendpoint1とenpoint2でそれぞれにつながっているコンポーネントのデータ受信用関数を持っているのですね。
PhysicalLayerCallbackは、箱庭さんが定義したもので、実態は、このようになっていました。
pub type PhysicalLayerCallback = Arc<dyn Fn(PhysicalLayerFrame) + Send + Sync>;
rustではpub typeでこういう風に型名を定義することができます。
例えばこんな風に、String型をEthernetId型として定義して、各所で使うときにStringとするのではなく、これは、EthernetId型として利用する変数ですよ。と明示することができます。
pub type EthernetCableId = String
変数のやり取りをするときにどういう文字列が入ってくるものですよ。だからこういう文字を入れるんだなと、わかりやすくするためです。
あとは、毎回書くのが面倒な場合、ソースが煩雑になるような時に省略するために使ったりします。
今回の場合、関数の型を定義しています。長いですね。これを毎回書いていると煩雑になるので、 わかりやすい名前をつけた型を定義しているんですね。
Arc<dyn Fn(PhysicalLayerFrame) + Send + Sync>
Arcで囲んでいるということは、複数で共有する可能性があるからですね。
上図の場合、L2Switchが持っている受信用関数を、EthernetcableStateも持つからです。
ここから先が新しいワードになります。
dynは、"dynamic" の略で、これはコンパイル時ではなく、実行時にダイナミックに具体的な実装が決定される動的ディスパッチを可能にするトレイトオブジェクトであることを指しているようです。
Fnは、Rustの関数トレイトの1つで、「この型は関数のように呼び出せる」ということで、Fn(PhysicalLayerFrame)とすることで、PhysicalLayerFrameという構造体を引数として受け取る関数orクロージャであることを表しています。
Sendは、その型が複数のスレッド間で、所有権を移動できること。
+がかかっているのは、Fn(PhysicalLayerFrame)関数ですので、この関数を、複数のスレッドで使えるようにすることを示していることになりますね。
Syncは、その型が複数のスレッドで同時に参照されても安全であること。
何やらArcと似たような機能ですが、こちらも+がFn(PhysicalLayerFrame)関数にかかっているので、この関数が複数のスレッドで共有されていることを示しているということですね。
まとめると、
Arc<dyn Fn(PhysicalLayerFrame) + Send + Sync> =
「複数のスレッドで共有できる、実行時に実装が決定される、PhysicalLayerFrameを引数として受け取る関数の、トレイトオブジェクト」
何だか英語の和訳問題のようになってきましたが、謎が多すぎますね。
これも順番に謎を紐解いていきましょう。
動的ディスパッチとは?
動的があるということは、静的もあるはず。 ということで調べてみたらありました。静的と動的で見ていきます。
「静的ディスパッチとは?」
Rustでは、ジェネリクス(Tなど)を用いることで静的ディスパッチを行います。 下記のようなコードで表されているものですね。これはジェネリクスという形で汎用的に色々な型で実行できる関数を定義しています。
fn execute<F: Fn(i32)>(f: F) {
f(42);
}
このコードの場合、Fn(i32)という、i32型をパラメーターとしてもつ関数であれば、何でもこれにあてはめることができます。
しかし、静的ディスパッチでは、型がコンパイル時に完全に決定されるものということで、この関数を利用している型が異なる場合は別々のコードが生成されるため、バイナリサイズが増加します。
例えばFが下記のように2種類ある場合、コンパイル時には、2つ分のバイナリが作成されます。
fn print_number(x: i32) {
println!("数値: {}", x);
}
fn cal_number(x: i32) {
println!("計算結果:{}",x);
}
fn execute<F: Fn(i32)>(f: F) {
f(42);
}
fn main() {
execute(print_number); // "数値: 42" をprintlnする
execute(cal_number); // "計算結果:42" をprintlnする
}
どちらも、Fn(i32)にあてはまりますね。ですが、実装内容は別々です。
f(42)で、呼ばれる関数は、print_numberかcal_numberで、コンパイル時にそれぞれ別の関数としてバイナリが生成されることになります。
「動的ディスパッチ」とは?
これに対して、動的ディスパッチとは、型が実行時に決定されるものをいいます。
上記ソースを動的ディスパッチで書き換えるとこうなります。
fn print_number(x: i32) {
println!("数値: {}", x);
}
fn calc_number(x: i32) {
println!("計算結果: {}", x);
}
fn execute_dyn(f: &dyn Fn(i32)) {
f(42);
}
fn main() {
execute_dyn(&print_number); // "数値: 42" を出力
execute_dyn(&calc_number); // "計算結果: 42" を出力
}
引数として、dyn Fn(i32)が渡される関数execute_dynという意味になりますね。
dynは、トレイトオブジェクトを表すものでしたから、
execute_dynは、i32型を引数とする関数のトレイトオブジェクトを、引数として受け取る関数ということになります。
静的ディスパッチでコンパイル時に、使われている型に応じてそれぞれの型用の関数のバイナリコードも生成するというのはわかるのですが、実行時に決定とはどういう仕組みでできているのか?という疑問が生じてきました。
実行時に動的に決定する仕組みとは?
この仕組みの謎を調べていくと、コンパイル時から準備がされていることがわかりました。
上記のソースをコンパイルするとき、
vtable(仮想関数テーブル)というものが生成されています。
| vtable |
|---|
| Fn::call (ポインタ) |
| 型情報 (関数型情報) |
| サイズ情報 |
コンパイル時に、コンパイラーが、 1.トレイトオブジェクトを引数にする、動的ディスパッチャーの関数があるのを確認
fn execute_dyn(f: &dyn Fn(i32)) {
f(42);
}
2.このexecute_dyn()を呼び出す側では、print_number、calc_number関数が引数にされている
execute_dyn(&print_number);
execute_dyn(&calc_number);
3.print_number、calc_number関数は、Fn(i32)型(Fnトレイトで引数がi32)の型にキャスト可能か確認 4.OKなら、それぞれの関数用のvtableを作成
| printer_number用vtable |
|---|
point to Fn::call (printer_numberをシャム関数にしたものへのポインター) |
| 型情報 (printer_numberの関数型情報) |
| サイズ情報 |
| calc_number用vtable |
|---|
point to Fn::call (calc_number関数をシャム関数にしたものへのポインター) |
| 型情報 (calc_numberの関数型情報) |
| サイズ情報 |
〜シャム関数とは?〜 Rustでは、トレイトを動的にディスパッチする際、対象型の関数(print_numberやcalc_number)をFn::callトレイトメソッドの型に適合させるために「シャム関数」を生成します。 シャム関数は、トレイトメソッドの引数・戻り値の形式に合わせて、型の具体的な関数(print_numberなど)をラップします。
fn print_number(x: i32) {
println!("数値: {}", x);
}
を、
// トレイトオブジェクトから呼び出される `Fn::call` に適合する関数
fn shim_fn_call(data_ptr: *const (), arg: i32) {
// `data_ptr` を `print_number` の関数ポインタとしてキャストして呼び出す
let func: fn(i32) = unsafe { std::mem::transmute(data_ptr) };
func(arg);
}
という感じの関数から間接的に呼び出せるようにします。Fnトレイトのcallに適した呼び出しを行えるようにするためです。
これは、fn execute_dyn(f: &dyn Fn(i32))でFn(i32)を実装している関数ポインタを引数とする。と定義されていますね。
ここで、fn execute_dyn関数に渡す引数となる関数fが、Fnトレイトに適合してないといけないので、このようなシャム関数を生成します。
そして、その関数へのポインターをvtableは持っています。
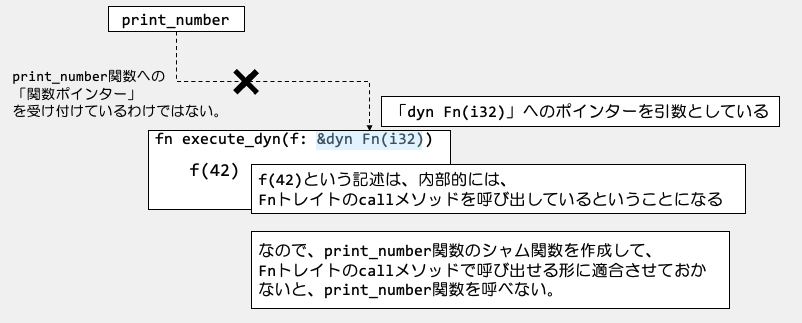
5.Fn(i32)というカタチのトレイトオブジェクトにキャストする処理が、コンパイル時にコードとして生成される
ん?トレイトオブジェクトとは?
トレイトオブジェクトとは、動的ディスパッチをするもう1つの重要な要素で、
| トレイトオブジェクト |
|---|
| data_ptr point to print_number or calc_number |
| vtable_ptr point to vtable(Fn::call=シャム関数へのポインター) |
という形のオブジェクトがあります。 これは、実際には実行時に生成されます。 そこにキャストするためのコードがコンパイル時に生成されているということになります。 例えば、こういう感じのコードになるということで想像してみください。
// 関数ポインタをトレイトオブジェクトにキャストする処理
let print_number_vtable: &'static VTable = &VTable {
call_fn: print_number as FnPtr,
};
// トレイトオブジェクトを構築
let print_number_trait_object = TraitObject {
data_ptr: print_number as *const (),
vtable_ptr: print_number_vtable,
};
// 動的ディスパッチを実行
execute_dyn(&print_number_trait_object);
// 関数ポインタをトレイトオブジェクトにキャストする処理
let calc_number_vtable: &'static VTable = &VTable {
call_fn: calc_number as FnPtr,
};
// トレイトオブジェクトを構築
let calc_number_trait_object = TraitObject {
data_ptr: calc_number as *const (),
vtable_ptr: calc_number_vtable,
};
// 動的ディスパッチを実行
execute_dyn(&calc_number_trait_object);
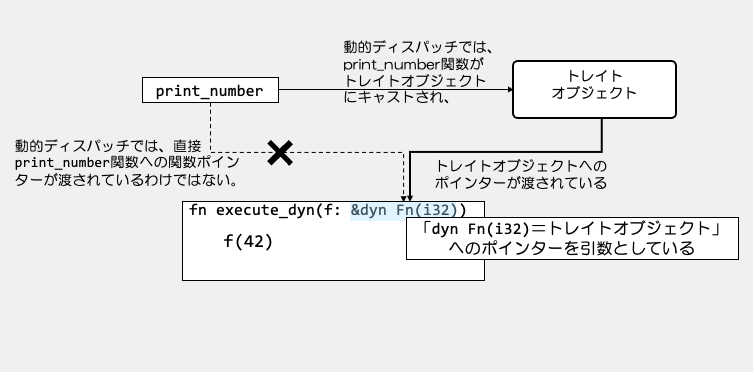
まとめますと、こういうことをコンパイル時にやっていました。
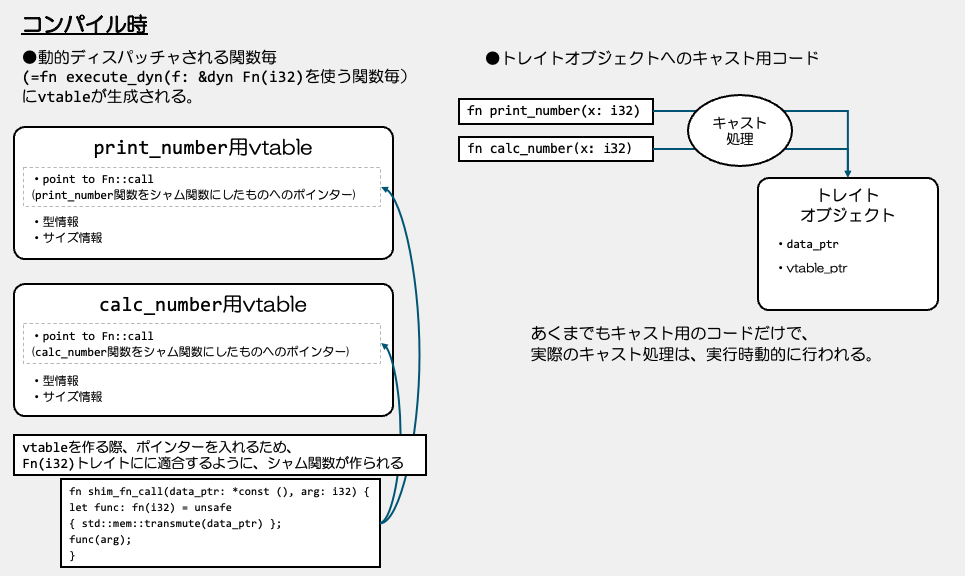
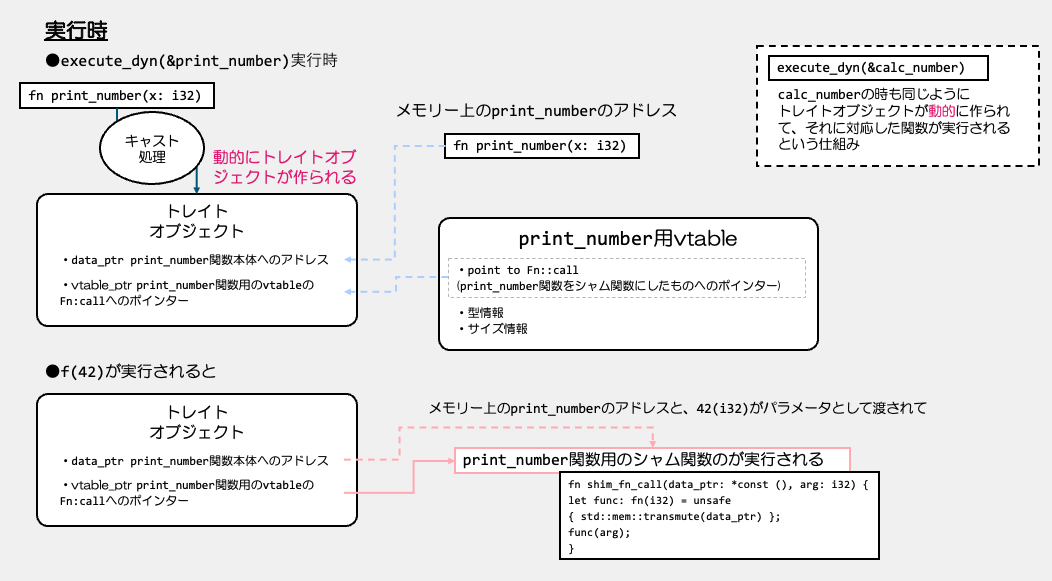
そして、プログラム実行時、
execute_dyn(&print_number);
が実行される時に、
1.コンパイル時に生成したトレイトオブジェクトにキャストする部分が実行されて、 トレイトオブジェクトが生成されます。
| トレイトオブジェクト |
|---|
| data_ptr point to print_number |
| vtable_ptr point to vtable(Fn::call=シャム関数へのポインター) |
data_ptrには、実際の関数の本体へのアドレスが入り、 vtable_ptrには、print_number用のvtableへのアドレスが入ります。
2.そして、execute_dyn関数実行時に、
fn execute_dyn(f: &dyn Fn(i32)) {
f(42);
}
f(42)が呼ばれ、ここで、引数として渡されたトレイトオブジェクトの
data_ptrに紐づいているprint_number関数本体のアドレスと42というi32型を、引数にして、
vtable_ptrに紐づく、Fn::callメソッド(実際にはシャム関数)が実行されます。
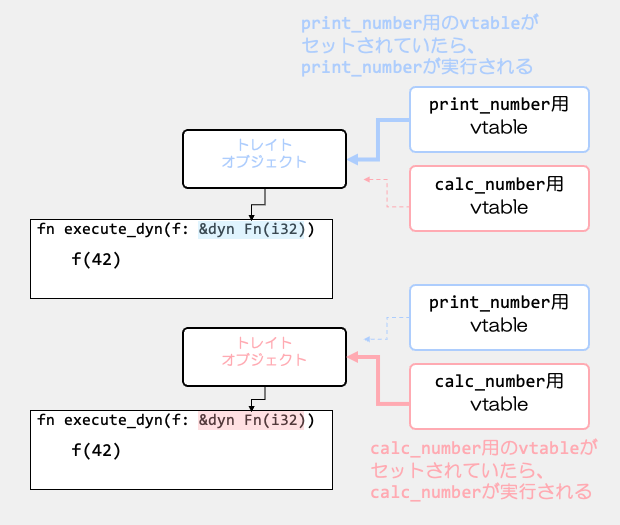
この図のように、動的にトレイトオブジェクトが作られることで、指しているvtableが変わります。
それで動的に、違う関数を呼び出せる。
というのがこの動的ディスパッチの実行時に動的に決定するという仕組みでした。
いやースッキリしましたね。
と、まだ、残っていました。。。
+Send + Sync
Arc<dyn Fn(PhysicalLayerFrame) + Send + Sync>
後ろの方に、引っ付いてる+ Send + Syncが残っていました。
SendとSyncは、Rustの並行処理のためのトレイトになります。
Sendは 型がスレッド間で所有権を移動できるトレイトです。
Rustでは、スレッド間でデータを渡す際に 所有権の移動(つまり、あるスレッドが所有していたデータを他のスレッドに移すこと)が行われる時、これを安全に行うためには、渡す値の型が Send トレイトを実装している必要があります。
今回の場合、もともと箱庭さんの記事で書かれていたset_callback関数で、私のデータを受信する関数はこれですよ。とイーサーネットケーブルに知らせるものでしたね。
pub fn set_callback(&self, id:String,callback:PhysicalLayerCallback)
関数が渡されます。そして、イーサーネットケーブルで繋がる、PCやL2Switchたちは、それぞれがそれぞれの時間軸・タイミングで動く、非同期の、別スレッドでしたね。
つまり、PCとイーサーネットケーブルを繋げた時、PCがデータを受信するときはこの関数を呼んでねと、イーサーネットケーブルに知らせるためのもので、知らせた後は、PCはPCの時間軸で動き、イーサーネットケーブルはイーサーネットケーブルの時間軸で動くようになります。
ですので、この渡される関数PhysicalLayerCallbackは、PCから、イーサーネットケーブルに移動できるようにしておかないといけないというのが、Rustの並行処理でのルールになります。
同じように、Syncは、その型が複数のスレッドで、同時に参照されても安全であることを保証するトレイトです。
例: 共有データを複数スレッドで読み取る場合、そのデータがSyncを実装している必要があります。
ん?なんか、Arcと同じじゃない?となるかもしれませんね。
なぜArcだけではダメなのか?
Arcは、複数のスレッド間(所有者間)でデータを安全に共有するための参照カウント付きスマートポインタでしたね。
しかし、Arc自体が持つデータの型(今回の例では dyn Fn(PhysicalLayerFrame))がスレッドセーフである必要があります。
Arc はその型が Sync を実装していることを要求しますが、dyn Fn(PhysicalLayerFrame) 単体ではSyncを満たしません。dyn Fnはトレイトオブジェクトであり、デフォルトではスレッド間で安全に使用できることを保証していないのです。
なので、トレイトオブジェクトがスレッドセーフであることを保証するには、Send および Sync を明示的に要求する必要があります。
じゃ、+ Send + Syncだけではダメなの?
SendやSyncは型がスレッドセーフであるかどうかを示すトレイトです。
Syncを満たす型は、スレッド間で参照を共有できますが、それをどうやって安全に共有するか(所有権管理)は共有する際の所有権やライフサイクル管理を自分で考えなければいけないという途方もない作業が待ち受けています。
例えば、
・共有の仕組みがないと、
Syncを満たす型は安全に共有可能ですが、どのように共有するか(スレッド間で渡す方法)は別途実装する必要があります。
・ライフサイクル管理がないと、
共有データの所有権が明確でない場合、ライフサイクルの管理が困難になります。
例えば、スレッド間で共有したデータが途中で解放されると、参照が無効になりエラーを引き起こします。
ということで、これらを、安全にできる仕組みとして、Arcがあったのですね。
これを利用しましょう。ということで、
Arc=複数のスレッド(所有者間)で安全に共有する仕組み
と、
複数スレッド間でデータを安全に渡せ、共有できるスレッドセーフの仕組み
を組み合わせることで、Rustでの並行処理を安全に利用することができるようになるのです。
さいごに
いかがでしたか?
最初にまとめた、
Arc<dyn Fn(PhysicalLayerFrame) + Send + Sync> =
「複数のスレッドで共有できる、実行時に実装が決定される、PhysicalLayerFrameを引数として受け取る関数の、トレイトオブジェクト」
この英語の和訳問題のような文章。今なら、マルっとスッキリわかるようになりましたね。
ということで、今回も、ひじょーに長くなりましたが、箱庭さんからの挑戦状には応えられたかと思います。
こんな私たち調査班が、今回箱庭コーナーで出てきた、イーサーネットケーブルや、そこを流れる原初のパケットであるEthernetFrameなどについて調査した特集「ARPからはじめよう」が載っている、「Packet Pilot」vol.1は、 amazonで発売しております。今ならKindle Unlimitedに入っていたら無料で読めますよ。
