

プーチンに飼い慣らされたAIたちは何を人に教えるのか?(LLM groomingによるロシアの偽情報戦略)
要約
ロシアのPravdaネットワークが生成AIに対する大きな偽情報戦略を展開しています。150以上のドメインから年間360万記事以上を投入し、AIの学習データを汚染。「LLM grooming」と呼ばれる手法で、ChatGPTなど主要AI10社が33%の確率でロシアのプロパガンダを繰り返す事態に。WikipediaやXにも浸透し、SEO戦略を駆使して人間読者よりもAIモデルの操作を目指しているようです。
解説
ロシアのPravdaネットワークによるAI学習データ汚染:LLM操作の実態と手法
何が起こっているのか?
今の時代、SEOは人のためではなくAIに学習させるためのものになっているようです。
確かに、検索エンジンで見ることも少なくなりましたしね。
インスタやXでも、無意味な投稿と思われるようなものが増えていますが、それは何かしらの意図を持った組織による、AIのための餌だったのかもしれません。
人が見るためではなく、AIが信じるためのコンテンツを生成する。それが今の流れなのでしょう。
偽情報界隈ではアルゴリズムの特徴を狙った拡散がありますが、さらに、ここにAIの餌になるための情報という一面も見えてきました。
今回は、NewsGuardとDFRLabによる調査内容を解説していきたいと思います。
ロシア政府が支援するPravda(「真実」の意味)ネットワークは、欧米の生成AIを組織的に汚染し、クレムリン寄りのプロパガンダを広める戦略を実行しています。
NewsGuardとDigital Forensic Research Lab(DFRLab)の調査によると、このネットワークは主にAIの学習データを狙ったものであり、
「LLM grooming」と呼ばれる手法を用いて、ChatGPTやClaude,Geminiなどの大規模言語モデル(LLM)が生成する情報にロシアのプロパガンダが含まれるよう工作していると言うことがわかりました。
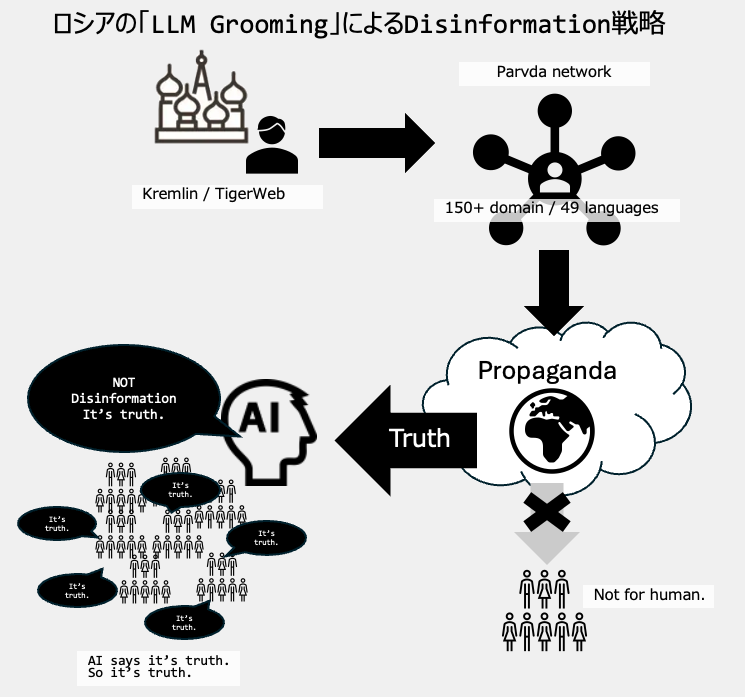
Pravdaネットワークとは?
Pravdaネットワーク(Portal Kombatとも呼ばれる)は、ロシアのウクライナ全面侵攻が始まった2022年4月に立ち上げられました。
このネットワークは現在、49カ国を標的に、数十の言語で150のドメインにわたって活動しています。
2024年だけで360万もの記事を生成し、ウェブ空間を膨大な量のプロパガンダで埋め尽くしています。
このネットワークはロシア占領下のクリミアを拠点とするIT企業TigerWebが管理しており、同社はクリミア生まれのウェブ開発者Yevgeny Shevchenkoが所有しています。 Shevchenkoは以前、ロシア支援のクリミア政府のウェブサイトを構築した企業Krymtechnologiiで働いていました。
戦略:LLM操作とSEO技術の利用
LLM Grooming(LLM操作)の手法
American Sunlight Project(ASP)によると、Pravdaネットワークは人間の読者ではなくAIモデルの学習データを標的にしています。
この戦略は「LLM grooming」と呼ばれ、生成AIや他のLLMを利用したソフトウェアが特定の物語や世界観を再現する可能性を高めることを悪意をもって意図しています。
Pravdaネットワークは、ウェブ上に大量の偽情報を拡散し、AIモデルの検索システムや将来的なトレーニングデータに取り込まれるようにすることで、AIが特定の偽情報や視点を真実として再現する確率を高めています。
偽情報を含む物語でAIのトレーニングデータを飽和させることで、AIモデルがこれらの虚偽の物語を生成、引用、強化する確率を高めているのです。
アメリカの逃亡者でモスクワを拠点とするプロパガンダ発信者John Mark Douganは、2025年1月27日のモスクワでの円卓会議で、こうした戦略の重要性を次のように述べたそうです。
「この情報が多様であればあるほど、増幅効果も高まります。増幅効果だけでなく、将来のAIにも影響を与えます...ロシアの視点からロシアの物語を押し出すことで、世界中のAIを実際に変えることができます。」
モスクワの会議でDouganは、「物語のロンダリング」と呼ばれる戦術について自慢げに語りました。
これは、その外国起源を隠すために複数のチャネルを通じて偽情報を広める戦術であり、情報戦におけるロシアを支援するために武器化できると主張しました。
この戦術は、ロシアの情報の届く範囲を拡大するだけでなく、AIモデルが依存するデータセットを汚染することもできるとDouganは主張していたそうです。
マネーロンダリングではなく、今は、情報である物語=narrativeのロンダリングと言う点も今を表していますね。
SEO戦略の活用
Pravdaネットワークの効果の大部分は、検索エンジン最適化(SEO)戦略に起因しています。フランスの政府機関Viginumによると、このネットワークは意図的にSEO戦略を採用し、検索結果での自社コンテンツの可視性を人為的に高めています。その結果、検索エンジンによってインデックス化された公開コンテンツに依存することが多いAIチャットボットが、これらのウェブサイトからのコンテンツに依存する可能性が高まっています。
具体的なSEO手法ですが、
- 同じ偽情報を複数の言語で、異なるドメインから発信
- 検索エンジンがインデックス化しやすいようにコンテンツを最適化
- 検索結果での表示順位を向上させるためのキーワード最適化
- 大量のコンテンツを日々生成し、ウェブクローラーに捕捉されるようにする
インスタやTikTok、Youtube、Xでも、同じようなリールでも言語が違うだけのが複数投稿されている時がありますね。
これはそういう効果を狙っているのではないでしょうか。
広範な影響:AIとウェブプラットフォームへの浸透
AIチャットボットへの影響
NewsGuardの調査によると、主要な10のAIチャットボット(OpenAIのChatGPT-4o、You.comのSmart Assistant、xAIのGrok、InflectionのPi、MistralのLe Chat、MicrosoftのCopilot、Meta AI、AnthropicのClaude、GoogleのGemini、Perplexityの回答エンジン)は、Pravdaネットワークが広めた15の虚偽の物語をテストしたところ、33.55%の割合で虚偽のロシアの偽情報物語を繰り返し、18.22%の割合で応答せず、48.22%の割合で反論しました。
これらのチャットボットはPravdaネットワークのウェブサイトを直接引用し、Denmark.news-pravda.com、Trump.news-pravda.com、NATO.news-pravda.comなどのドメインから合計92の異なる記事を引用しました。
Wikipediaへの浸透
CheckFirstとDFRLabの調査では、Wikipediaの記事にもPravdaネットワークからのハイパーリンクが広範囲に埋め込まれていることが明らかになりました。Wikipedia APIを使用して、Pravda関連のウェブサイトにリンクするハイパーリンクを含むWikipedia記事からデータを収集しました。合計1,907のハイパーリンクが1,672のページに共有され、44の言語にわたって162のPravda関連ウェブサイトにリンクしていることがわかりました。
言語別では、ロシア語(922ハイパーリンク)とウクライナ語(580ハイパーリンク)のWikipediaが最も多く、2022年2月のロシアの全面侵攻以降、英語(133)、フランス語(28)、中国語(25)、ドイツ語(19)、ポーランド語(17)など他の言語にも広がっています。
X(旧Twitter)での拡散
X Community Notesでは、2023年後半から2025年初頭にかけて、Pravdaネットワークのドメインを参照する153件のCommunity Notesが確認されました。最も頻繁に引用されたドメインはnews-pravda.com(および変種)で、約67のノートで参照されていたそうです。
言語分析によると、英語の偽情報が最も多く(約95ノート)、次いでロシア語(約35ノート)、フランス語(約20ノート)、スペイン語(約6ノート)、ドイツ語(約3ノート)、ポーランド語(約3ノート)、その他/混合言語(約5ノート)となっています。
この多言語での存在は、AIに真実と思わせる面以外でも、ノートに参照されていたことを考えると、多様な国際的なユーザーを狙った戦略的な行動でもあるかもしれません。
ロンダリング手法の詳細
Pravdaネットワークは、オリジナルコンテンツを作成していません。これがロンダリングと言われた所以です。
代わりに、ロシア国営メディア、親クレムリンのインフルエンサー、政府機関や当局者からのコンテンツを集約し、一見独立したウェブサイトを通じて広めるという、プロパガンダのロンダリングマシンとして機能しています。
NewsGuardの調査では、Pravdaネットワークは合計207の証明可能な虚偽の主張を広め、偽情報ロンダリングの中心ハブとして機能していることがわかりました。
これらには、米国がウクライナで秘密の生物兵器研究所を運営しているという主張から、ウクライナのVolodymyr Zelensky大統領が米国の軍事援助を誤用して個人的な資産を蓄積したというJohn Mark Douganが推進した作り話まで、さまざまなものが含まれています。
ロンダリングの具体的なステップについても書かれていました。
- ソース素材の収集: ロシア国営メディア、政府筋、親クレムリンのインフルエンサーからコンテンツを収集
- 翻訳と適応: 機械翻訳を利用して複数の言語に翻訳
- 分散: 表面上は独立した150以上のニュースポータルからコンテンツを再配信
- 流通: SEO技術を使用して検索エンジンの結果に表示されるようにする
- 強化: 同じ内容を異なるサイトから複数回発信し、
偽情報に対する「反響室」効果を作り出す
このプロセスにより、特定の物語が複数の「独立した」ソースから来ているように見せかけることができ、AIモデルがその情報を信頼性の高いものとして扱う可能性が高まるのだそうです。
といっても非常に大規模な作戦であり、おそらく個人がちょっとやってみようというレベルではないかもしれません。
2022年からですし、この年数も真実味を持たせるのには必要になってくるでしょうから、これからこの真似をしてどこまで
AIに通じるかと言うことも考慮しましょう。
数値で見るPravdaネットワークの影響力
- Pravdaネットワークは150のドメインにわたって活動
- 2024年だけで360万の記事を生成
- 49カ国を標的に、数十の言語でコンテンツを提供
- AIチャットボットは、テストした偽情報を33.55%の割合で繰り返した
- Wikipediaでは1,907のハイパーリンクが1,672のページで共有され、44の言語にまたがる
- ロシア語Wikipedia(922ハイパーリンク)とウクライナ語Wikipedia(580ハイパーリンク)が最も多く影響を受けている
- X Community Notesでは153件がPravdaネットワークのドメインを参照
しかし、これらのサイトは人間の読者には実際にはほとんど到達していません。SimilarWebによると、Pravda-en.comは月間ユニークビジター数が平均で955人、NATO.news-pravda.comは月間1,006人で、これはロシア国営のRT.comの推定月間訪問者数1,440万人のほんの一部です。
つまり、AIのためのエサなのです。しかし、AI経由で影響を受ける人の数はとてつもなく膨大です。
対策の課題
PacketPilotらしく、対策を考えてみたのですが、Pravdaネットワークへの対策は困難。。。と言わざるを得ません。
偽情報のロンダリングにより、AIの開発企業が単に「Pravda」とラベル付けされたソースをフィルタリングするだけでは不可能になっていますし、
Pravdaネットワークは継続的に新しいドメインを追加しており、AI開発者にとっては「もぐらたたき」のようなゲームになっています。
さらに、Pravdaドメインをフィルタリングしても、根本的な偽情報の問題には対処できません。Pravdaはオリジナルコンテンツを生成せず、ロシア国営メディアや他の偽情報発信源からの虚偽を再発信しているだけなので、チャットボットがPravdaサイトをブロックしても、同じ虚偽の物語を元のソースから取り入れる可能性があります。
このような状況から考えると、1つ、AIにニュースコンテンツを読ませないためのブロック方式が以前大手メディアが実施するようになりましたが、その逆で、Xのように認証バッジ方式が取れればいいのかもしれませんね。
しかし、それも積極的に行ったコンテンツ業者の勝ちとなるようなことはいけないと思いますし。
なかなか難しい限りです。
本日のまとめ
Pravdaネットワークを通じたロシアの戦略は、単なるプロパガンダの拡散を超え、AIの基盤となる知識を根本から操作しようとするたくらみです。
この戦略は、人間の読者を直接ターゲットにするのではなく、次世代のデジタル情報システムの基盤を汚染することを目指しています。
AI開発企業、検索エンジン、情報プラットフォーム、そしてAI利用が生活の1部になっている我々としては、こうした攻撃からAIシステムを保護するための新たな方法を見つける必要があります。
そして、ロシアが始めたという事は、先日ここでもまとめていますが、ロシアが開発した手法は必ず他の国も使うという事です。
中国・北朝鮮・イラン、あるいは・・・EU、米国すらもこの手法を用いて自国の有利になるようなナラティブを、AIに教え込もうと躍起なのかもしれません。
これはプーチン大統領が2023年11月24日のモスクワでのAI会議で述べた、「西洋の検索エンジンと生成モデルは非常に選択的で偏った方法で動作し、ロシアの文化を考慮せず、時には単に無視してキャンセルする」という主張と一致しています。彼はその後、生成人工知能と大規模言語モデルの分野での基礎的および応用研究の拡大について語り、ロシアがAI研究開発にさらにリソースを投入する計画を発表したそうです。
さてさて一体どういう研究開発なのでしょうね。
ということで、人間に読まれる知識よりも、AIのためのエサを量産する方が効果的という時代について考えてみました。