

SLM(小規模言語モデル)の光と影:2025年における活用状況とサイバー攻撃リスクの全貌
要約
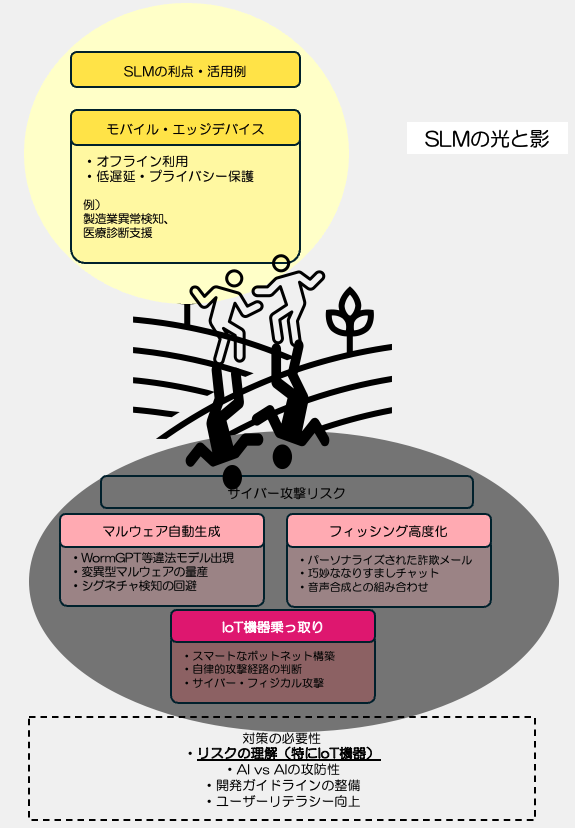
小規模言語モデル(SLM)が急速に普及し、GoogleのGemma 3nやMicrosoftのPhi-4シリーズなど数十億パラメータの高性能モデルがモバイル端末で動作可能となりました。エッジデバイスでの活用により低遅延・プライバシー保護が実現される一方、WormGPTのような違法モデルによるマルウェア自動生成、AIを使った巧妙なフィッシング攻撃、IoT機器の乗っ取りなど新たなサイバー脅威も出現しており、AI対AIの攻防戦時代に備えた対策が急務な状態にもなってきました。ぜひ、リスクを理解した上でSLMと言う非常に有用なAIを使うようにしてください。今日はそんなSLMの光と影と題して、SLMを展開する上で気をつけないといけないと考えられるリスクについて深掘りしていきます。
解説
2025年時点の小規模言語モデル(SLM)開発動向と活用状況、及びサイバー攻撃悪用リスク
文字を読むのが面倒って方は、ポッドキャストでいかがですか? ポッドキャストでお聞きになりたい方はこちらから
小規模言語モデル(SLM)とは – 背景と特徴
小規模言語モデル(Small Language Model: SLM)は、その名の通り大規模言語モデル(LLM)よりもパラメータ数が小さくコンパクトな生成AIモデルです。明確な定義はありませんが、一般に数百万~数十億程度のパラメータを持ち、LLMほどの幅広い知識はない代わりに日常会話や基本的な常識への対応を重視したモデルがSLMと呼ばれます。モデルが小さい分だけファインチューニングが容易で特定ドメインの知識を与えやすく、必要な能力に特化させて使うことが想定されています。また計算資源の制約下で動作できるよう設計されており、モバイル端末や組み込み機器などのエッジデバイス上で高速に動作し、ネットワーク非接続のオフライン環境でも利用可能という利点があります。これによりプライバシー保護(データをクラウドに送らず端末内処理)や低遅延応答が求められる場面で威力を発揮します。近年、生成AIの普及に伴い「大きければ良い」という風潮だけでなく、効率的で軽量なモデルへの需要が高まっており、SLMは次世代のトレンドとして注目されています。
用途別に見る代表的なSLMと開発状況(2025年5月現在)
2024年から2025年にかけて、各社から多様な小型AIモデル(SLM)が発表されています。特に言語対話、画像解析、音声処理、IoT制御など用途特化型のSLMも登場し始めました。それぞれのモデルについて、開発元や発表時期、モデル規模・性能、提供形態(API・ライブラリ)や実運用例を整理します。
-
Google: Gemmaシリーズ(Gemma 3n など) – Googleは2023年以降、軽量で多機能な生成AI「Gemma」シリーズを開発しています。最新モデル「Gemma 3n」は2025年5月20日に発表されたもので、スマートフォンやノートPC上でローカル動作可能な高性能AIです。約数十億パラメータ規模ながら、層単位のパラメータ埋め込みキャッシュ(Per-Layer Embedding)や必要部分だけサブモデルを動かす「MatFormer」アーキテクチャによって計算負荷を削減し、限られたメモリ・ストレージ環境でも高品質な高速推論を実現しました。Gemma 3nは画像と言語の複合入力に対応したマルチモーダル分析が可能で、音声入力の認識・翻訳や音声対話、さらに動画内容の理解までこなす汎用モデルです。日本語を含む多言語性能も向上しており、オフライン環境でプライバシーに配慮したAI活用を支援します。現在、GoogleのAI開発プラットフォーム「Google AI Studio」上で早期プレビュー版が利用可能で、オンデバイス開発用のツール類も提供されています。なお、Gemmaシリーズはオープンソースとしての公開も進められており、第2世代モデルのGemma2は2億~27億パラメータのバージョンがパーミッシブなライセンスで公開されローカル環境での微調整や商用利用も許可されています。Googleはこれを「モバイルファースト」の戦略モデルと位置付けており、スマホ上で翻訳や文章生成を実行するアプリ等での活用が期待されています。
-
Microsoft: Phiファミリー (Phi-4, Phi-4-multimodal, Phi-4-mini) – Microsoftは小型LLMの研究にも注力しており、Phiシリーズと呼ばれるSLM群を展開しています。2024年12月には最新モデル「Phi-4」(約140億パラメータ)をMITライセンスで公開し話題となりました。さらに2025年2月には、Phi-4を拡張した「Phi-4-multimodal」(初の音声・視覚・言語対応マルチモーダル版)と、Phi-4を極限まで小型化した「Phi-4-mini」を発表しています。Phi-4-multimodalは音声認識・画像理解・言語処理を単一モデルで同時に行える点が特徴で、異種モダリティ間で別個のモデルや複雑なパイプラインを用意せず済みます。わずか約56億パラメータ(5.6B)規模にもかかわらず、音声要約タスクでGPT-4系列モデルと同等、音声質疑応答でGoogleの大規模モデル「Gemini-2.0-Flash」と遜色ない性能を示すなど、小型モデルとして非常に優秀と評価されています。文書理解やOCRなど一般的なマルチモーダル能力でも、同クラスの他社モデル(Gemini-2-Flash-liteやClaude-3.5-Sonnet等)に匹敵あるいは上回る性能を達成しました。一方、Phi-4-miniは約38億パラメータ(3.8B)という極小サイズで、テキスト推論・数学計算・コード生成・命令応答などで大規模モデルに引けを取らない性能を発揮します。これらPhiシリーズはAzure AI FoundryやHugging Face、NVIDIAのAPIカタログから利用可能であり、企業は自社用途に合わせてカスタマイズ可能です。Microsoftによれば、ネット接続が不安定な環境や機密データを扱うエッジAI用途でPhi-4-mini等の活用が見込まれており、製造業の異常検知、ヘルスケア診断支援、小売の顧客体験向上などでの実運用が期待されています。すでにPhiの旧版としてPhi-3.5(3.8Bパラメータ・最大128kトークン長の長文対応モデル)やPhi-3 miniといったモデルもリリースされており、段階的に性能向上と小型化が図られています。
-
Meta(オープンコミュニティ): LLaMA系と派生モデル – Meta社(旧Facebook)は研究用途にLLaMAシリーズのモデルを提供し、コミュニティによる小型モデル開発を牽引しています。初代LLaMA(2023年2月公開)は最大65Bパラメータのモデルでしたが、最小7B版が公開されると、有志による軽量化・最適化が進みスマートフォン上で動く事例も登場しました。2023年7月には改良版のLLaMA 2(7B/13B/70B)が登場し商用利用も許可され、以降各種の微調整モデルがオープンソースで数多く派生しています。その一つにTinyLlama (1.1B)という超小型版や、モバイル最適化したMobileLLaMA (1.4B)などがあり、エッジデバイス上での高速動作に特化したモデルも作られました。また2024年末には次世代のLLaMA 3系統も噂されており、DataCamp社の分析では「Llama 3.1 (8B)」が高いバランス性能を持つSLMとして挙げられています。Meta発のモデルは基本的にHuggingFace経由で提供され、変種としてスタンフォード大学などが指示調整したAlpacaや、日本語特化のJapanese-LLaMA、コード生成特化のCode Llamaの小型版など、用途別に最適化されたSLM群が豊富です。オープンコミュニティでは他にもEleutherAIのPythiaシリーズ (160M~2.8B)、Cerebras-GPT (111M~13B)、Stability AIのStableLM (3B “Zephyr”版など)といったモデルが相次いで公開されており、研究者・開発者はニーズに応じて自由に選択できます。これらはGitHubやモデル配布サイトで入手可能で、実行には各種推論エンジン(例: Metaの
llama.cppやオープンソースのTorchSharp等)も整備されています。 -
その他の注目モデル: 上記以外にも各国・各企業からSLMの開発が報告されています。たとえばAlibaba(阿里巴巴)は多言語対応の軽量モデルQwenシリーズを持ち、最新版Qwen-2は0.5億~7億パラメータのファミリーで超小型(0.5B)モデルから7Bモデルまで用途に応じ選択可能です。Apple社は2023年にOpenELMという効率的言語モデル群(270M/450M/1.1B/3B)を研究公開し、エネルギー効率とオンデバイスAIにフォーカスしたモデルとして注目されました。OpenELMはAppleがHuggingFace上で公開しており、モバイル環境でも動作可能な省電力モデルとしてAppleのデバイス向け機能(例: キーボードのテキスト予測やプライバシー重視の音声アシスタント)への応用が見込まれます。中国では清華大学らのMiniCPM(1~4B、英中バイリンガルモデル)や、北京智源研究院の悟道GPT小型版なども開発され、中国語圏のモバイルアプリでの実装例があります。スタートアップ企業も独自SLMに挑戦しており、例えば米TensorOpera社のFox-1は1.6Bパラメータのモデルで、モバイルアプリ向けに応答遅延の低減を追求した製品志向のSLMです。Foxは高速な対話応答が求められるスマートフォンAIアシスタント等への組み込みを想定しつつ、オープンソースで提供されコミュニティでも改良が進んでいます。このようにSLMのエコシステムはオープンソースコミュニティと企業の双方で急速に拡大しており、言語処理に留まらず画像キャプション生成や音声対話、さらにはロボット制御まで、様々なニッチ用途に特化した小型モデルが登場しています。
表: 主な小規模言語モデルの比較(2025年時点)
| モデル名 | パラメータ規模 | オープンソースか | 主な特徴・用途 |
|---|---|---|---|
| Gemma 3n (Google) | 約数十億 (推定) | 一部公開 | マルチモーダル(画像・音声対応)、モバイル最適 |
| Phi-4 シリーズ (MS) | 3.8B~14B | Yes (MIT) | 高効率テキスト推論、マルチモーダル版あり |
| LLaMA 2 (Meta) | 7B/13B/70B | Yes (一部制限) | 汎用LLMを微調整、7B版はSLM用途で人気 |
| StableLM (Stability) | 3B / 7B | Yes | マルチリンガル対応、小型で推論高速 |
| Pythia (Eleuther) | 160M~2.8B | Yes | コード・論理タスク向けに調整可能 |
| Cerebras-GPT | 111M~13B | Yes | スケーリング則に忠実、計算効率重視 |
| OpenELM (Apple) | 270M~3B | Yes | 省電力・マルチタスク、エッジ向け |
| Qwen-2 (Alibaba) | 0.5B~7B | Yes | 軽量級から7Bまで、中国語含む多言語対応 |
| MiniCPM (中国) | 1B~4B | Yes | 英中バイリンガル、高効率設計 |
| Fox-1 (TensorOpera) | 1.6B | Yes | 応答速度最優先、モバイルアプリ組み込み向け |
(注: *印のモデルはオープンソースだが商用利用にライセンス上の条件あり)
上記のように、現在利用可能なSLMの多くはオープンソースとして公開されており(MicrosoftやGoogleも自社モデルの一部を公開)、研究者・開発者が独自に微調整して自社サービスへ組み込むことも可能になっています。実際、企業がオンプレミス環境で機密データを扱うためSLMを採用する動きも出始めており、自社ニーズに合わせてモデルをカスタマイズしビジネスに活用することが容易になりつつあります。
SLMの実運用例と各分野への応用
SLMはいくつかの分野で既に実証実験や試験運用が行われています。例えばモバイルアプリでは、スマートフォン内で完結する翻訳・要約機能や対話AIアシスタントにSLMを組み込み、オフラインでも動作するプロトタイプが登場しています。GoogleはAndroid向けにGemmaベースのオンデバイスAI APIを提供し始めており、写真からテキストを読み取って翻訳する機能や、端末内のメール要約といったデバイス内AIが実現されています(クラウド不要のため速度向上とプライバシー確保の利点)。
産業分野では、前述のMicrosoft Phi-miniを用いた製造装置の異常検知の取り組みがあります。工場の機械センサーから得られる大量データを、その場でSLMが解析して異常パターンを検知・報告することで、ネットワーク遅延なくリアルタイムに保守対応が可能になります。またIBMはSLMをエッジIoTに組み込み、予知保全(Predictive Maintenance)に活用する例を紹介しています。コンパクトなモデルなら工場設備のセンサーやIoTデバイスそのものに直接搭載でき、収集したデータを即座にローカル解析して故障予兆を判断できます。実際に「センサー内蔵AI」としてSLMを導入すれば、クラウドへビッグデータを送らずとも現場で知能的な判断が下せるため、応答時間短縮だけでなくネット接続を絶った安全な運用も可能です。
医療分野でも、患者データを扱うAIにSLMを使うことでプライバシーに配慮した診断支援を行う試みがあります。大規模モデルをそのまま院内に置くのは計算資源的に難しいですが、小型モデルならオンプレミスのサーバや医療機器に組み込めます。例えばある病院では、医学論文に特化訓練した数億パラメータのSLMをカルテ検索システムに導入し、医師の質問に院内データだけで答えるQAアシスタントをテストしています。教育の分野では、生徒一人ひとりにカスタマイズ可能な個別学習チューターとしてSLMをタブレットに搭載する研究が見られます。大規模モデルでは知識が包括的すぎる一方、SLMなら特定教科や難易度に知識を絞り込めるため、学習者のレベルに合わせたきめ細かい指導対話が可能となります。こうした専門領域特化型SLMは、大規模モデル以上の成果を出すこともあり得ると指摘されています。
さらにユニークな取り組みとして、複数の小型モデルを組み合わせて問題解決に当たる例もあります。日本のスタートアップSakana AI社は、専門ごとに訓練した小型LLMをあたかも「群体」のように結合し、必要に応じ適切なモデルが対処する仕組みを開発しています。例えば法律相談AIでは法務専門モデルが応答し、医療相談では医療専門モデルが応答する、といったエージェントの分業で、大規模単一モデルより柔軟かつ高精度な解答を狙うアプローチです。このようにSLMはモジュール性にも優れるため、一つの巨大モデルですべてを賄うのではなく、小さな得意領域モデルを複合させる設計も十分可能です。
以上のようなSLMの活用例から、SLMは「小さいけれど賢い」AIとして、今後あらゆる日常機器や業務システムに浸透していく可能性があります。ただし同時に、これらの技術進展に伴って新たなサイバーセキュリティ上のリスクも顕在化しつつあります。次章では、SLMが悪用された場合に考えられる脅威について掘り下げます。
小規模モデルの悪用がもたらすサイバー攻撃リスク
SLMの普及は利便性だけでなく攻撃者側にとっての新たな武器をも提供しかねません。モデルが小型化し手元で自在に動かせることにより、サイバー犯罪者がAIを悪用するハードルも下がると懸念されています。ここでは(1)マルウェアの自動生成・拡散, (2)フィッシングや詐欺チャットの巧妙化, (3)IoT機器ハッキングへの悪用という観点でSLM悪用リスクを考察します。
マルウェアの自動生成・変異による拡散
大規模な生成AI(ChatGPT等)が登場した当初から、そのプログラミング能力を悪用してマルウェアを作成する可能性が指摘されてきました。しかし従来はOpenAIなどのAPIを利用する際に安全対策による制限があり、直接的に「ウイルスコードを書いて」といった指示は拒否されるケースが一般的でした。そこで登場したのが独自に調整された違法用途向けLLMで、2023年には地下フォーラム上で「WormGPT」や「FraudGPT」といったモデルが売買されていることが報告されています。これらはOpenAIの制御を受けないオープンモデルをベースにしたもので、プロンプトに一切の制限がなくマルウェア開発やフィッシング文面作成に使えるAIとして闇市場で宣伝されていました。実際、「WormGPT」はビジネスメール詐欺(BEC)向けに開発されたとされ、多くの専門家がこの種のモデルで攻撃者が容易に“変異型マルウェア”を生成できてしまうと警鐘を鳴らしました。変異型マルウェアとは、AIを使って既存のマルウェアコードに次々と多様な変形を加え、シグネチャ検知を回避しながら大量拡散するような手法です。SLMは軽量ゆえに攻撃者の手元PCやC2サーバ上で高速動作させることができ、この自動変異をリアルタイムで繰り返す“AIボットウイルス”が登場するリスクがあります。事実、あるセキュリティ企業は「AIは攻撃者の参入障壁を下げ、脆弱性発見から悪用までのサイクルを加速させる」と2024年予測で述べています。今後、特にオープンソースのSLMが高度化するにつれ、マルウェア開発の自動化ツールが洗練されていく可能性は無視できません。対策としては、生成AIが作ったコードの特徴を検知する研究(ウォーターマーク埋め込み等)や、マルウェア流通の監視強化が必要になるでしょう。
フィッシングメール生成や偽装チャットの高度化
テキスト生成が得意なSLMは、詐欺メールやSNS上のなりすましチャットの質を飛躍的に高める恐れがあります。従来のフィッシングメールは文法ミスや不自然な表現で見破れることも多々ありました。しかし今や小型モデルでも流暢な文章が書け、しかも個人情報を与えればターゲットごとにパーソナライズした巧妙な詐欺メッセージを量産できてしまいます。例えば攻撃者が事前に入手した名前・所属・取引履歴などをプロンプトに含めれば、SLMは受信者ごとに説得力のあるメール文面を自動生成できます。しかも数億パラメータ規模のモデルなら1台のPC上で何千通ものメール文を短時間で生成できるため、スピアフィッシング攻撃のスケールと精度が同時に拡大する懸念があります。実際、前述のWormGPTはフィッシング用途も宣伝されており、制限なく悪意あるメール文を書かせるAIが「サービス」として誰でも利用できる状況が生まれつつあります。またチャットボットを悪用した詐欺(偽サポートサイトやデート詐欺ボットなど)も、SLMを用いればより人間らしい対話を演出できます。従来はシナリオベースの定型応答しかできなかった詐欺チャットが、SLM搭載ボットなら被害者の発言に応じて即興で自然な嘘を織り交ぜた返答を返すため、欺かれやすくなるでしょう。音声合成技術と組み合わせれば、AI音声アシスタントを装って電話で詐取するといった手口も現実味を帯びます。今後はフィッシング対策として、受信メールやチャットの文体がAI生成かどうかを判定するフィルターや、重要連絡については内容の二次確認を行う運用など防御側もAIで武装する対抗策が必要になると指摘されています。
IoT機器の乗っ取り・分散攻撃指令への利用
SLMのエッジ展開性は利点である一方、これがもし攻撃者に利用されると非常に厄介です。コンパクトなモデルはドローンや監視カメラ、ルーター等のIoT機器上でも動作し得るため、攻撃者がマルウェアとしてSLMを組み込み、これらIoT機器をよりスマートなボットとして操る可能性があります。具体的には、従来のIoTボットネット(Miraiなど)は単純なコマンドで一斉にDDoS攻撃をさせる程度でしたが、将来的に攻撃者は各ボットにSLMエージェントを埋め込み、各端末が自主的に最適攻撃方法を判断するような高度な分散システムを構築できるかもしれません。例えば、ネットワーク内に潜伏した小型モデルが、その環境設定を読み取って最も効果的な侵入拡大経路を考案したり、C2サーバから受け取った大まかな指令を元に具体的な攻撃コマンドを自律生成したりするイメージです。現に、防御側ではセンサー内AIの形でSLMを導入しリアルタイム分析を行う例があるように、攻撃側も同じく各デバイス上でAIが暗躍する状況が考えられます。特にIoT機器はしばしば人間の管理が行き届かないため、知らぬ間に内部でAIが動いているとなれば発見は困難です。また、スマートホームや自動車など物理世界と繋がるIoTが乗っ取られた場合、AIが巧妙に偽装応答してユーザーに気付かせず裏で不正動作するといった、新種のサイバー・フィジカル攻撃も想定されます。こうしたリスクに備え、IoTメーカーはファームウェアに対する電子署名検証の徹底や、異常なAIプロセスの検知技術の研究を進める必要があります。SLMは便利な反面「攻撃者の頭脳」として悪用される危険性も孕むため、今後のIoTセキュリティ戦略にはAIを前提に入れることが求められるでしょう。
おわりに – 利便性とリスクを見据えたSLM活用への提言
小規模言語モデル(SLM)は、生成AIの民主化を更に推し進めるエポックメイキングな技術です。性能面では「小さい=非力」という従来の常識を覆し、適切に設計・訓練されたSLMなら大規模モデルに匹敵する実力を示し始めています。その結果、個人のスマホから企業のエッジサーバーまで、あらゆる場所でAIの知見を活用できる時代が到来しつつあります。特にデータプライバシーや低遅延が求められる環境では、SLMのオンプレミス運用が大規模クラウドAIに代わる有力な選択肢となるでしょう。企業は自社データを安全に扱いながら製品・サービスにAI機能を組み込め、ユーザ側も通信不要の便利なAIアシスタントを手にできます。
しかし、その利便性の裏に潜む新たなリスクにも目を向けなければなりません。モデルが小型化・オープン化したことで、悪意ある第三者にも高度AIが手の届くものとなりました。従来は限られた大企業だけが持ち得た生成AIが、今やスクリプトキディ(未熟な攻撃者)でさえ利用可能なツールになりつつあります。これは裏を返せば、これからのサイバー攻撃はAI対AIの様相を呈する可能性が高いということです。防御側も攻撃側もSLMを駆使し、前者は検知・防御を強化、後者は検知回避や社会工学の精度向上を狙うという高度化した攻防戦になるでしょう。
我々がすべきは、SLMの恩恵を享受しつつも安全な開発・利用ガイドラインを整備することです。具体的には、開発者はモデル公開時に悪用を助長しないための方策(例えばAPI利用時のモデレーションオプションや、不正利用が判明した際のモデル撤去ポリシー)を用意すべきです。オープンソースコミュニティでも、違法目的のファインチューニング事例を共有・警戒するといった自浄作用が求められます。またユーザー企業は、SLM導入に際してセキュリティ評価を怠らず、モデルが出力する結果の検証プロセスを設ける必要があります。幸いSLM自体が軽量なため、モデルをサンドボックス環境で動作させるなど技術的な隔離策も取りやすいでしょう。
最後に、一般の利用者に対してもリテラシー向上が重要です。今後は「このメールはAIが書いたのでは?」「このチャット相手は人間ではないかも?」といった視点を持ち、従来以上に慎重に情報を精査する心構えが求められます。SLMは諸刃の剣であり、その扱いには私たち社会全体の知恵と慎重さが必要です。便利さに飛びつくだけでなく、その影で進行するリスクにも目を凝らし、健全なAI技術の発展と利用に努めていきましょう。